Chapter 3 Data
3.1 Starting out
We will start by opening RStudio. Ideally, you will have already installed both R and Rstudio before the workshop. If you have not done this already, then please see the Setting up your computer section. During this workshop, please do not copy and paste code from the workshop manual into RStudio. Instead, please write it out yourself in an R script. When programming, you will spend a lot of time fixing coding mistakes—that is, debugging your code—so it is best to get used to making mistakes now when you have people here to help you. You can create a new R script by clicking on File in the RStudio menu bar, then New File, and then R Script.
After creating a new script, you will notice that a new Source panel has appeared. In the Source panel, you can type and edit code before you run it. You can run code in the Source panel by placing the cursor (i.e., the blinking line) on the desired line of code and pressing Control + Enter on your keyboard (or CMD + Enter if you are using an Apple computer). You can save the code in the Source panel by pressing Control + s on your keyboard (or CMD + s if you are using an Apple computer).
You can also make notes and write your answers to the workshop questions inside the R script. When writing notes and answers, add a # symbol so that the text following the # symbol is treated as a comment and not code. This means that you don’t have to worry about highlighting specific parts of the script to avoid errors.
# this is a comment and R will ignore this text if you run it
# R will run the code below because it does not start with a # symbol
print("this is not a comment")## [1] "this is not a comment"# you can also add comments to the same line of R code too
print("this is also not a comment") # but this is a comment## [1] "this is also not a comment"Remember to save your script regularly to ensure that you don’t lose anything in the event that RStudio crashes (e.g., using Control + s or CMD + s)!
3.2 Setting up the R session
Now we will set up our R session for the workshop. Specifically, enter the following R code to attach the R packages used in this workshop.
# load packages
library(prioritizr) # package for conservation planning
library(tidyverse) # package for data wrangling
library(terra) # package for working with raster data
library(sf) # package for working with vector data
library(highs) # package provides HiGHS solver
library(mapview) # package for creating interactive maps
library(units) # package for unit conversions
library(scales) # package for rescaling numbers
# setup printing for tables
## show all rows in tables
options(pillar.print_max = Inf)You should have already downloaded the data for the prioritizr workshop. If you have not already done so, you can download it from here: https://github.com/prioritizr/workshop/raw/main/data.zip. After downloading the data, you can unzip the data into a new folder. Next, you will need to set the working directory to this new folder. To achieve this, click on the Session button on the RStudio menu bar, then click Set Working Directory, and then Choose Directory.
Now navigate to the folder where you unzipped the data and select Open. You can verify that you have correctly set the working directory using the following R code. You should see the output TRUE in the Console panel.
file.exists("data/pu.gpkg")## [1] TRUE3.3 Data import
Now that we have downloaded the dataset, we will need to import it into our R session. Specifically, this data was obtained from the “Introduction to Marxan” course and the Australian Government’s National Vegetation Information System. It contains vector-based planning unit data (pu.gpkg) and the raster-based data describing the spatial distributions of 33 vegetation classes (vegetation.tif) in Tasmania, Australia. Please note this dataset is only provided for teaching purposes and should not be used for any real-world conservation planning. We can import the data into our R session using the following code.
# import planning unit data
## note that read_sf is from the sf package
pu_data <- read_sf("data/pu.gpkg")
# import vegetation data
## note that rast() is from the terra package
veg_data <- rast("data/vegetation.tif")3.4 Planning unit data
The planning unit data contains spatial data describing the geometry for each planning unit and attribute data with information about each planning unit (e.g., cost values). Let’s investigate the pu_data object. The planning unit data contains 5 columns with the following information:
id: unique identifiers for each planning unitcost: acquisition cost values for each planning unit (millions of Australian dollars).locked_in: logical values (i.e.,TRUE/FALSE) indicating if planning units are covered by protected areas or not.locked_out: logical values (i.e.,TRUE/FALSE) indicating if planning units cannot be managed as a protected area because they contain are too degraded.geom: spatial geometries for the planning units.
# print the first six rows of the planning unit data
head(pu_data)## Simple feature collection with 6 features and 4 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 303910.1 ymin: 5485840 xmax: 335610.4 ymax: 5502544
## Projected CRS: WGS 84 / UTM zone 55S
## # A tibble: 6 × 5
## id cost locked_in locked_out geom
## <int> <dbl> <lgl> <lgl> <MULTIPOLYGON [m]>
## 1 1 60.2 FALSE TRUE (((328497 5497704, 326783.8 5500050, 326775.…
## 2 2 19.9 FALSE FALSE (((307121.6 5490487, 305344.4 5492917, 30538…
## 3 3 59.7 FALSE TRUE (((321726.1 5492382, 320111 5494593, 320127 …
## 4 4 32.4 FALSE FALSE (((304314.5 5494324, 304342.2 5494287, 30432…
## 5 5 26.2 FALSE FALSE (((314958.5 5487057, 312336 5490646, 312339.…
## 6 6 51.3 FALSE TRUE (((327904.3 5491218, 326594.6 5493012, 32849…# plot maps of the planning unit data, showing each of the columns
plot(pu_data)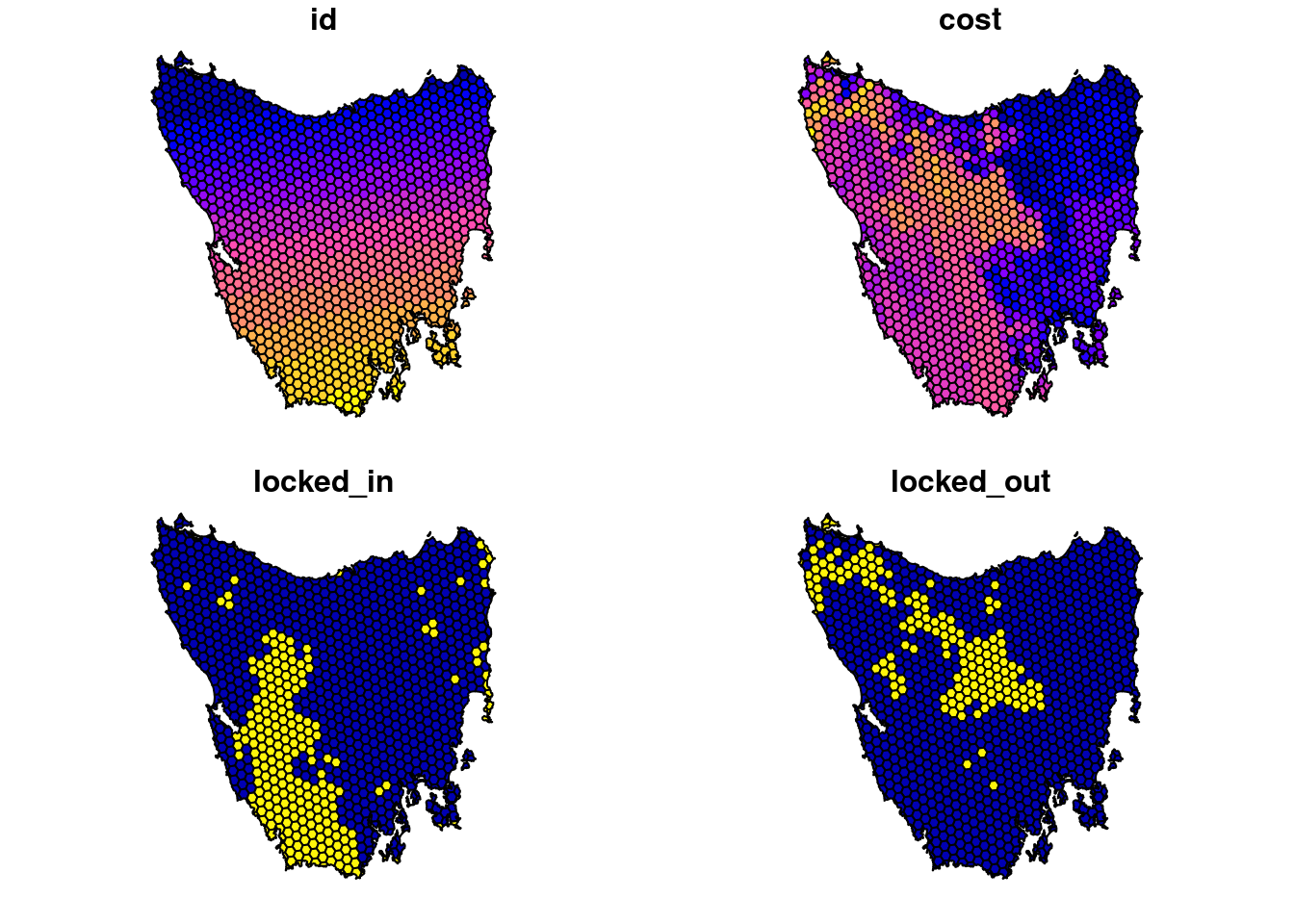
# print number of planning units (geometries) in the data
nrow(pu_data)## [1] 1130# print the highest cost value
max(pu_data$cost)## [1] 61.92727# print the smallest cost value
min(pu_data$cost)## [1] 0.1924883# print average cost value
mean(pu_data$cost)## [1] 25.13536# plot a map of the planning unit cost data
plot(pu_data[, "cost"])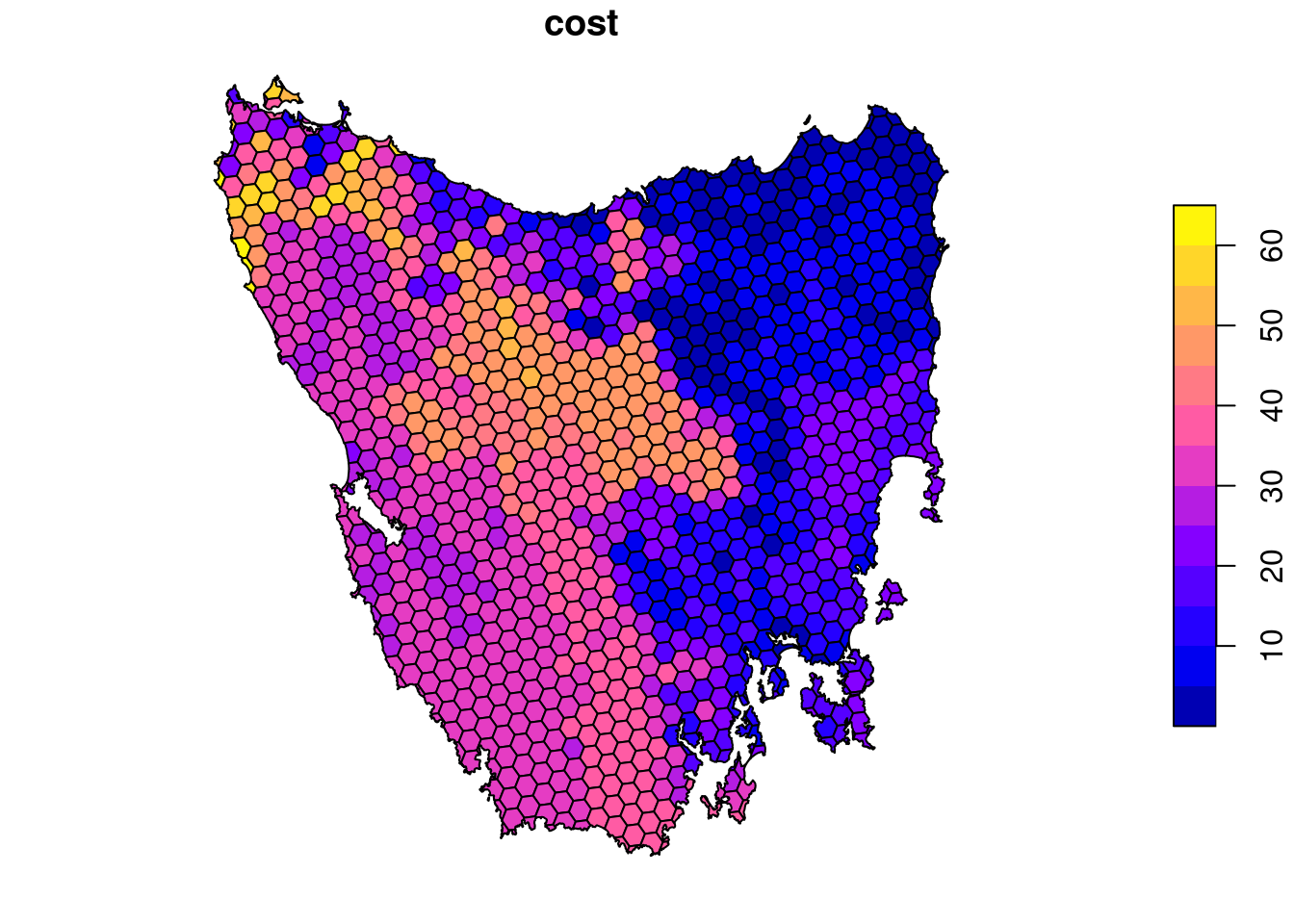
# plot an interactive map of the planning unit cost data
mapview(pu_data, zcol = "cost")Now, you can try and answer some questions about the planning unit data.
- How many planning units are in the planning unit data?
- What is the highest cost value?
- How many planning units are covered by the protected areas (hint:
sum(x))? - What is the proportion of the planning units that are covered by the protected areas (hint:
mean(x))? - How many planning units are highly degraded (hint:
sum(x))? - What is the proportion of planning units are highly degraded (hint:
mean(x))? - Can you verify that all values in the
locked_inandlocked_outcolumns are zero or one (hint:min(x)andmax(x))?. - Can you verify that none of the planning units are missing cost values (hint:
all(is.finite(x)))?. - Can you very that none of the planning units have duplicated identifiers? (hint:
sum(duplicated(x)))? - Is there a spatial pattern in the planning unit cost values (hint: use
plot(x)to make a map). - Is there a spatial pattern in where most planning units are covered by protected areas (hint: use
plot(x)to make a map).
3.5 Vegetation data
The vegetation data describes the spatial distribution of 33 vegetation classes in the study area. This data is in a raster format and so the data are organized using a square grid comprising square grid cells that are each the same size. In our case, the raster data contains multiple layers (also called “bands”) and each layer has corresponds to a spatial grid with exactly the same area and has exactly the same dimensionality (i.e., number of rows, columns, and cells). In this dataset, there are 33 different regular spatial grids layered on top of each other – with each layer corresponding to a different vegetation class – and each of these layers contains a grid with 398 rows, 359 columns, and 142882 cells. Within each layer, each cell corresponds to a 1 by 1 km square. The values associated with each grid cell indicate the (one) presence or (zero) absence of a given vegetation class in the cell.
Let’s explore the vegetation data.
# print a short summary of the data
print(veg_data)## class : SpatRaster
## dimensions : 398, 359, 33 (nrow, ncol, nlyr)
## resolution : 1000, 1000 (x, y)
## extent : 288801.7, 647801.7, 5142976, 5540976 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 55S (EPSG:32755)
## source : vegetation.tif
## names : Banks~lands, Bould~marks, Calli~lands, Cool ~orest, Eucal~hyll), Eucal~torey, ...
## min values : 0, 0, 0, 0, 0, 0, ...
## max values : 1, 1, 1, 1, 1, 1, ...# print number of layers in the data
nlyr(veg_data)## [1] 33# print the name of each layer
names(veg_data)## [1] "Banksia woodlands"
## [2] "Boulders/rock with algae, lichen or scattered plants, or alpine fjaeldmarks"
## [3] "Callitris forests and woodlands"
## [4] "Cool temperate rainforest"
## [5] "Eucalyptus (+/- tall) open forest with a dense broad-leaved and/or tree-fern understorey (wet sclerophyll)"
## [6] "Eucalyptus open forests with a shrubby understorey"
## [7] "Eucalyptus open woodlands with shrubby understorey"
## [8] "Eucalyptus tall open forest with a fine-leaved shrubby understorey"
## [9] "Eucalyptus tall open forests and open forests with ferns, herbs, sedges, rushes or wet tussock grasses"
## [10] "Eucalyptus woodlands with a shrubby understorey"
## [11] "Eucalyptus woodlands with a tussock grass understorey"
## [12] "Eucalyptus woodlands with ferns, herbs, sedges, rushes or wet tussock grassland"
## [13] "Freshwater, dams, lakes, lagoons or aquatic plants"
## [14] "Heathlands"
## [15] "Leptospermum forests and woodlands"
## [16] "Low closed forest or tall closed shrublands (including Acacia, Melaleuca and Banksia)"
## [17] "Mallee with a tussock grass understorey"
## [18] "Melaleuca open forests and woodlands"
## [19] "Melaleuca shrublands and open shrublands"
## [20] "Mixed chenopod, samphire +/- forbs"
## [21] "Naturally bare, sand, rock, claypan, mudflat"
## [22] "Other Acacia tall open shrublands and shrublands"
## [23] "Other forests and woodlands"
## [24] "Other open woodlands"
## [25] "Other shrublands"
## [26] "Other tussock grasslands"
## [27] "Regrowth or modified forests and woodlands"
## [28] "Saline or brackish sedgelands or grasslands"
## [29] "Salt lakes and lagoons"
## [30] "Sedgelands, rushs or reeds"
## [31] "Temperate tussock grasslands"
## [32] "Unclassified native vegetation"
## [33] "Wet tussock grassland with herbs, sedges or rushes, herblands or ferns"# layers can be accessed using indices or names,
## for example the 30th class is "Sedgelands, rushs or reeds"
## and we can make a map of it using the index or the name
# plot a map of the 30th class using the index
plot(veg_data[[30]])
# plot a map of the 30th class using its layer name
plot(veg_data[["Sedgelands, rushs or reeds"]])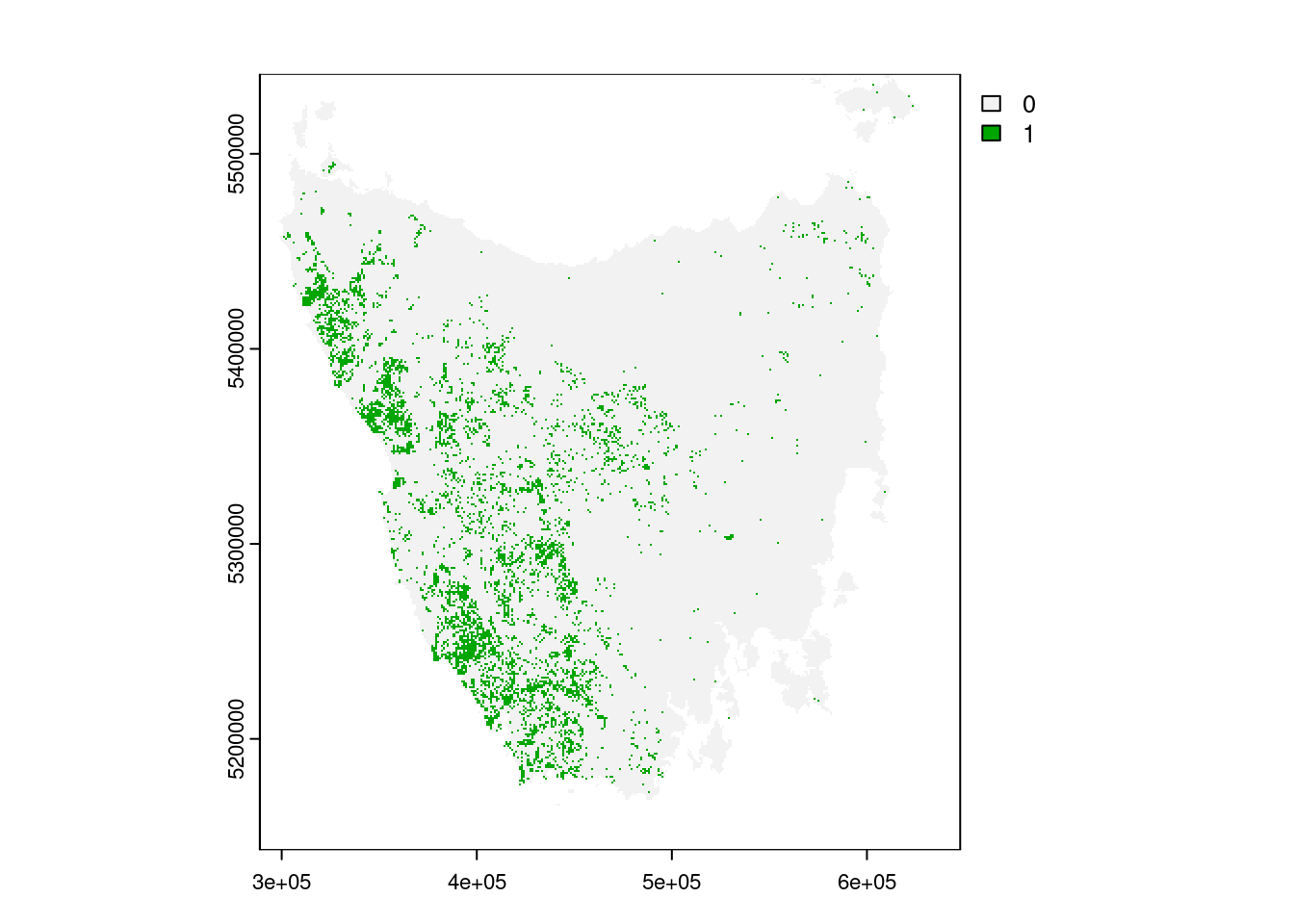
# plot an interactive map of the 30th class
## note that we use method = "ngb" because the data are not continuous
veg_data2 <- as(veg_data, "Raster")
mapview(veg_data2[[30]], method = "ngb")# print resolution on the x-axis
xres(veg_data)## [1] 1000# print resolution on the y-axis
yres(veg_data)## [1] 1000# print spatial extent of the grid, i.e., coordinates for corners
ext(veg_data)## SpatExtent : 288801.732237428, 647801.732237428, 5142975.76801917, 5540975.76801917 (xmin, xmax, ymin, ymax)# print a summary of the first layer
print(veg_data[[1]])## class : SpatRaster
## dimensions : 398, 359, 1 (nrow, ncol, nlyr)
## resolution : 1000, 1000 (x, y)
## extent : 288801.7, 647801.7, 5142976, 5540976 (xmin, xmax, ymin, ymax)
## coord. ref. : WGS 84 / UTM zone 55S (EPSG:32755)
## source : vegetation.tif
## name : Banksia woodlands
## min value : 0
## max value : 1# calculate the sum of all the cell values in the first layer
global(veg_data[[1]], "sum", na.rm = TRUE)## sum
## Banksia woodlands 2# calculate the maximum value of all the cell values in the first layer
global(veg_data[[1]], "max", na.rm = TRUE)## max
## Banksia woodlands 1# calculate the minimum value of all the cell values in the first layer
global(veg_data[[1]], "min", na.rm = TRUE)## min
## Banksia woodlands 0# calculate the mean value of all the cell values in the first layer
global(veg_data[[1]], "mean", na.rm = TRUE)## mean
## Banksia woodlands 3.021559e-05# calculate the maximum value in each layer
as_tibble(global(veg_data, "max", na.rm = TRUE), rownames = "feature")## # A tibble: 33 × 2
## feature max
## <chr> <dbl>
## 1 Banksia woodlands 1
## 2 Boulders/rock with algae, lichen or scattered plants, or alpine fjaeld… 1
## 3 Callitris forests and woodlands 1
## 4 Cool temperate rainforest 1
## 5 Eucalyptus (+/- tall) open forest with a dense broad-leaved and/or tre… 1
## 6 Eucalyptus open forests with a shrubby understorey 1
## 7 Eucalyptus open woodlands with shrubby understorey 1
## 8 Eucalyptus tall open forest with a fine-leaved shrubby understorey 1
## 9 Eucalyptus tall open forests and open forests with ferns, herbs, sedge… 1
## 10 Eucalyptus woodlands with a shrubby understorey 1
## 11 Eucalyptus woodlands with a tussock grass understorey 1
## 12 Eucalyptus woodlands with ferns, herbs, sedges, rushes or wet tussock … 1
## 13 Freshwater, dams, lakes, lagoons or aquatic plants 1
## 14 Heathlands 1
## 15 Leptospermum forests and woodlands 1
## 16 Low closed forest or tall closed shrublands (including Acacia, Melaleu… 1
## 17 Mallee with a tussock grass understorey 1
## 18 Melaleuca open forests and woodlands 1
## 19 Melaleuca shrublands and open shrublands 1
## 20 Mixed chenopod, samphire +/- forbs 1
## 21 Naturally bare, sand, rock, claypan, mudflat 1
## 22 Other Acacia tall open shrublands and shrublands 1
## 23 Other forests and woodlands 1
## 24 Other open woodlands 1
## 25 Other shrublands 1
## 26 Other tussock grasslands 1
## 27 Regrowth or modified forests and woodlands 1
## 28 Saline or brackish sedgelands or grasslands 1
## 29 Salt lakes and lagoons 1
## 30 Sedgelands, rushs or reeds 1
## 31 Temperate tussock grasslands 1
## 32 Unclassified native vegetation 1
## 33 Wet tussock grassland with herbs, sedges or rushes, herblands or ferns 1Now, you can try and answer some questions about the vegetation data.
- What part of the study area is the “Temperate tussock grasslands” vegetation class found in (hint: make a map)?
- What proportion of cells contain the “Heathland” vegetation class (hint: calculate the mean value of the cells)?
- Which vegetation class is present in the greatest number of cells?
- The planning unit data and the vegetation data should have the same coordinate reference system. Can you check if they are the same?