Chapter 4 Gap analysis
4.1 Introduction
Before we begin to prioritize areas for protected area establishment, we should first understand how well existing protected areas are conserving our biodiversity features (i.e. native vegetation classes in Tasmania, Australia). This step is critical: we cannot develop plans to improve conservation of biodiversity if we don’t understand how well existing policies are currently conserving biodiversity! To achieve this, we can perform a “gap analysis”. A gap analysis involves calculating how well each of our biodiversity features (i.e. vegetation classes in this exercise) are represented (covered) by protected areas. Next, we compare current representation by protected areas of each feature (e.g. 5% of their spatial distribution covered by protected areas) to a target threshold (e.g. 20% of their spatial distribution covered by protected areas). This target threshold denotes the minimum amount (e.g. minimum proportion of spatial distribution) that we need of each feature to be represented in the protected area system. Ideally, targets should be based on an estimate of how much area or habitat is needed for ecosystem function or species persistence. In practice, targets are generally set using simple rules of thumb (e.g. 10% or 20%), policy (17%; https://www.cbd.int/sp/targets/rationale/target-11) or standard practices (e.g. setting targets for species based on geographic range size) (Butchart et al. 2015; Rodrigues et al. 2004).
4.2 Feature abundance
Now we will perform some preliminary calculations to explore the data. First, we will calculate how much of each vegetation feature occurs inside each planning unit (i.e. the abundance of the features). To achieve this, we will use the problem function to create an empty conservation planning problem that only contains the planning unit and biodiversity data. We will then use the feature_abundances function to calculate the total amount of each feature in each planning unit.
# create prioritizr problem with only the data
p0 <- problem(pu_data, veg_data, cost_column = "cost")
# print empty problem,
# we can see that only the cost and feature data are defined
print(p0)## Conservation Problem
## planning units: SpatialPolygonsDataFrame (1130 units)
## cost: min: 0.19249, max: 61.92727
## features: vegetation.1, vegetation.2, vegetation.3, ... (62 features)
## objective: none
## targets: none
## decisions: default
## constraints: <none>
## penalties: <none>
## portfolio: default
## solver: default# calculate amount of each feature in each planning unit
abundance_data <- feature_abundances(p0)
# print abundance data
print(abundance_data)## # A tibble: 62 x 3
## feature absolute_abundance relative_abundance
## <chr> <dbl> <dbl>
## 1 vegetation.1 33 1
## 2 vegetation.2 173 1
## 3 vegetation.3 24 1
## 4 vegetation.4 31 1
## 5 vegetation.5 23 1
## 6 vegetation.6 22 1
## 7 vegetation.7 15 1
## 8 vegetation.8 45 1
## 9 vegetation.9 384 1
## 10 vegetation.10 14 1
## # … with 52 more rows# note that only the first ten rows are printed,
# this is because the abundance_data object is a tibble (i.e. tbl_df) object
# and not a standard data.frame object
print(class(abundance_data))## [1] "tbl_df" "tbl" "data.frame"# we can print all of the rows in abundance_data like this
print(abundance_data, n = Inf)## # A tibble: 62 x 3
## feature absolute_abundance relative_abundance
## <chr> <dbl> <dbl>
## 1 vegetation.1 33 1
## 2 vegetation.2 173 1
## 3 vegetation.3 24 1
## 4 vegetation.4 31 1
## 5 vegetation.5 23 1
## 6 vegetation.6 22 1
## 7 vegetation.7 15 1
## 8 vegetation.8 45 1
## 9 vegetation.9 384 1
## 10 vegetation.10 14 1
## 11 vegetation.11 39 1
## 12 vegetation.12 26 1
## 13 vegetation.13 20 1
## 14 vegetation.14 123 1
## 15 vegetation.15 18 1
## 16 vegetation.16 11 1
## 17 vegetation.17 24 1
## 18 vegetation.18 19 1
## 19 vegetation.19 24 1
## 20 vegetation.20 895 1
## 21 vegetation.21 258 1
## 22 vegetation.22 8 1
## 23 vegetation.23 10 1
## 24 vegetation.24 21 1
## 25 vegetation.25 13 1
## 26 vegetation.26 9 1
## 27 vegetation.27 15 1
## 28 vegetation.28 660 1
## 29 vegetation.29 30 1
## 30 vegetation.30 26 1
## 31 vegetation.31 52 1
## 32 vegetation.32 30 1
## 33 vegetation.33 312 1
## 34 vegetation.34 36 1
## 35 vegetation.35 173 1
## 36 vegetation.36 714 1
## 37 vegetation.37 26 1
## 38 vegetation.38 17 1
## 39 vegetation.39 18 1
## 40 vegetation.40 28 1
## 41 vegetation.41 59 1
## 42 vegetation.42 9 1
## 43 vegetation.43 80 1
## 44 vegetation.44 139 1
## 45 vegetation.45 40 1
## 46 vegetation.46 25 1
## 47 vegetation.47 24 1
## 48 vegetation.48 224 1
## 49 vegetation.49 4 1
## 50 vegetation.50 41 1
## 51 vegetation.51 223 1
## 52 vegetation.52 2 1
## 53 vegetation.53 4 1
## 54 vegetation.54 5 1
## 55 vegetation.55 7 1
## 56 vegetation.56 8 1
## 57 vegetation.57 18 1
## 58 vegetation.58 4 1
## 59 vegetation.59 36 1
## 60 vegetation.60 2 1
## 61 vegetation.61 0 NaN
## 62 vegetation.62 1 1The abundance_data object contains three columns. The feature column contains the name of each feature (derived from names(veg_data)), the absolute_abundance column contains the total amount of each feature in all the planning units, and the relative_abundance column contains the total amount of each feature in the planning units expressed as a proportion of the total amount in the underlying raster data. Since all the raster cells containing vegetation overlap with the planning units, all of the values in the relative_abundance column are equal to one (meaning 100%)—except for the 61st feature which has a value on NaN because it does not occur in the study area at all (i.e. all of its raster values are zeros). Now let’s add a new column with the feature abundances expressed in area units (i.e. km2).
# add new column with feature abundances in km^2
abundance_data$absolute_abundance_km2 <-
(abundance_data$absolute_abundance * prod(res(veg_data))) %>%
set_units(m^2) %>%
set_units(km^2)
# print abundance data
print(abundance_data)## # A tibble: 62 x 4
## feature absolute_abundance relative_abundan… absolute_abundance_k…
## <chr> <dbl> <dbl> [km^2]
## 1 vegetation.1 33 1 33
## 2 vegetation.2 173 1 173
## 3 vegetation.3 24 1 24
## 4 vegetation.4 31 1 31
## 5 vegetation.5 23 1 23
## 6 vegetation.6 22 1 22
## 7 vegetation.7 15 1 15
## 8 vegetation.8 45 1 45
## 9 vegetation.9 384 1 384
## 10 vegetation.10 14 1 14
## # … with 52 more rowsNow let’s explore the abundance data.
# calculate the average abundance of the features
mean(abundance_data$absolute_abundance_km2)## 86.67742 [km^2]# plot histogram of the features' abundances
hist(abundance_data$absolute_abundance_km2, main = "Feature abundances")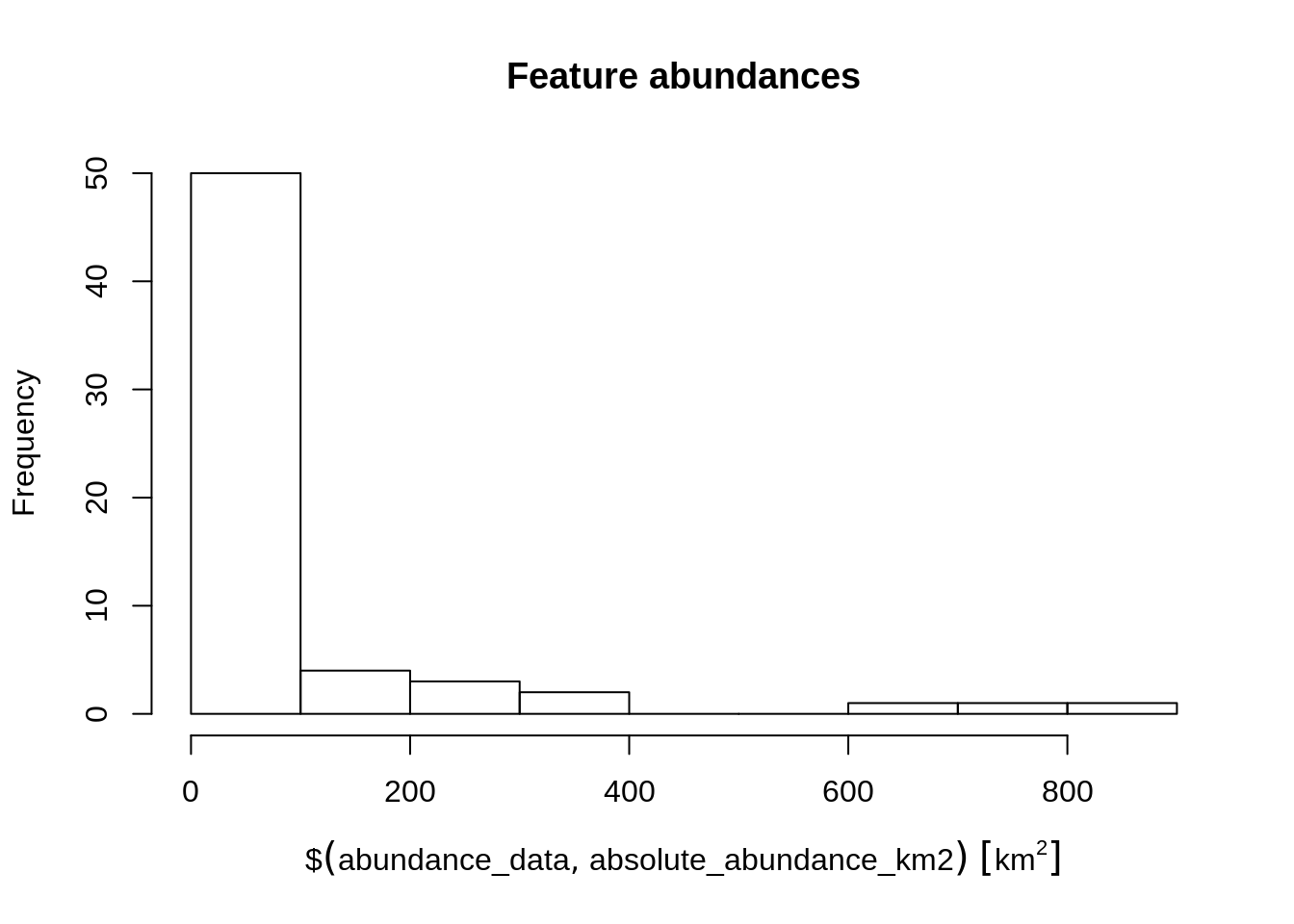
# find the abundance of the feature with the largest abundance
max(abundance_data$absolute_abundance_km2)## 895 [km^2]# find the name of the feature with the largest abundance
abundance_data$feature[which.max(abundance_data$absolute_abundance_km2)]## [1] "vegetation.20"Now, try to answer the following questions.
- What is the median abundance of the features (hint:
median)? - What is the abundance of the feature with smallest abundance?
- What is the name of the feature with smallest abundance?
- What is the total abundance of all features in the planning units summed together?
- How many features have a total abundance greater than 100 km^2 (hint:
sum(abundance_values > set_units(threshold_value, km^2))?
4.3 Feature representation by protected areas
After calculating the total amount of each feature in the planning units (i.e. the features’ abundances), we will now calculate the amount of each feature in the planning units that are covered by protected areas (i.e. feature representation by protected areas). We can complete this task using the feature_representation function. This function requires (i) a conservation problem object with the planning unit and biodiversity data and also (ii) an object representing a solution to the problem (i.e an object in the same format as the planning unit data with values indicating if the planning units are selected or not).
# create column in planning unit data with binary values (zeros and ones)
# indicating if a planning unit is covered by protected areas or not
pu_data$pa_status <- as.numeric(pu_data$locked_in)
# calculate feature representation by protected areas
repr_data <- feature_representation(p0, pu_data[, "pa_status"])
# print feature representation data
print(repr_data)## # A tibble: 62 x 3
## feature absolute_held relative_held
## <chr> <dbl> <dbl>
## 1 vegetation.1 1 0.0303
## 2 vegetation.2 14 0.0809
## 3 vegetation.3 2 0.0833
## 4 vegetation.4 1 0.0323
## 5 vegetation.5 0 0
## 6 vegetation.6 0 0
## 7 vegetation.7 0 0
## 8 vegetation.8 6 0.133
## 9 vegetation.9 20 0.0521
## 10 vegetation.10 0 0
## # … with 52 more rowsSimilar to the abundance data before, the repr_data object contains three columns. The feature column contains the name of each feature, the absolute_held column shows the total amount of each feature held in the solution (i.e. the planning units covered by protected areas), and the relative_held column shows the proportion of each feature held in the solution (i.e. the proportion of each feature’s spatial distribution held in protected areas). Since the absolute_held values correspond to the number of grid cells in the veg_data object with overlap with protected areas, let’s convert them to area units (i.e. km2) so we can report them.
# add new column with the areas represented in km^2
repr_data$absolute_held_km2 <-
(repr_data$absolute_held * prod(res(veg_data))) %>%
set_units(m^2) %>%
set_units(km^2)
# print representation data
print(repr_data)## # A tibble: 62 x 4
## feature absolute_held relative_held absolute_held_km2
## <chr> <dbl> <dbl> [km^2]
## 1 vegetation.1 1 0.0303 1
## 2 vegetation.2 14 0.0809 14
## 3 vegetation.3 2 0.0833 2
## 4 vegetation.4 1 0.0323 1
## 5 vegetation.5 0 0 0
## 6 vegetation.6 0 0 0
## 7 vegetation.7 0 0 0
## 8 vegetation.8 6 0.133 6
## 9 vegetation.9 20 0.0521 20
## 10 vegetation.10 0 0 0
## # … with 52 more rowsNow let’s investigate how well the species are represented.
- What is the average proportion of the features held in protected areas (hint:
mean(x, na.rm = TRUE)? - What is the average amount of land in km2 that features are represented by protected areas?
- What is the name of the feature with the greatest proportionate coverage by protected areas?
- What is the name of the feature with the greatest area coverage by protected areas?
- Do questions two and three have the same answer? Why could this be?
- Is there a relationship between the total abundance of a feature and how well it is represented by protected areas (hint:
plot(abundances ~ relative_held))? - Are any features entirely missing from protected areas (hint:
sum(x == 0))? - If we set a target of 10% coverage by protected areas, how many features fail to meet this target (hint:
sum(relative_held >= target, na.rm = TRUE))? - If we set a target of 20% coverage by protected areas, how many features fail to meet this target?
References
Butchart, S.H., Clarke, M., Smith, R.J., Sykes, R.E., Scharlemann, J.P., Harfoot, M., Buchanan, G.M., Angulo, A., Balmford, A., Bertzky, B., Brooks, T.M., Carpenter, K.E., Comeros-Raynal, M.T., Cornell, J., Ficetola, G.F., Fishpool, L.D., Fuller, R.A., Geldmann, J., Harwell, H., Hilton-Taylor, C., Hoffmann, M., Joolia, A., Joppa, L., Kingston, N., May, I., Milam, A., Polidoro, B., Ralph, G., Richman, N., Rondinini, C., Segan, D.B., Skolnik, B., Spalding, M.D., Stuart, S.N., Symes, A., Taylor, J., Visconti, P., Watson, J.E., Wood, L. & Burgess, N.D. (2015). Shortfalls and solutions for meeting national and global conservation area targets. Conservation Letters, 8, 329–337.
Rodrigues, A.S.L., Akçakaya, H.R., Andelman, S.J., Bakarr, M.I., Boitani, L., Brooks, T.M., Chanson, J.S., Fishpool, L.D.C., Da Fonseca, G.A.B., Gaston, K.J., Hoffmann, M., Marquet, P.A., Pilgrim, J.D., Pressey, R.L., Schipper, J., Sechrest, W., Stuart, S.N., Underhill, L.G., Waller, R.W., Watts, M.E.J. & Yan, X. (2004). Global gap analysis: Priority regions for expanding the global protected-area network. BioScience, 54, 1092–1100.